
2022-08-06
654

原创
Redis基本数据结构-dict
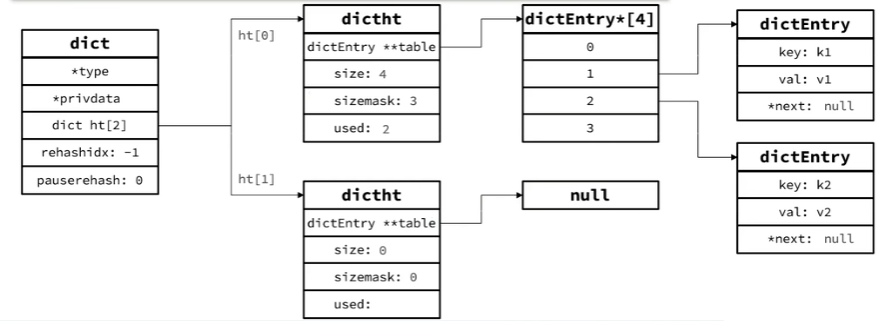
Redis是一个键值型(Key-Value Pair)的数据库,可以根据键实现快速的增删改查。而键与值的映射关系正是通过Dict来实现的。
当我们向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用h & sizemask来计算元素应该存储到数组中的哪个索引位置。我们存储k1=v1,假设k1的哈希值h =1,则1&3 =1,因此k=v1要存储到数组角标1位置

dict总览图
Dict的扩容
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。
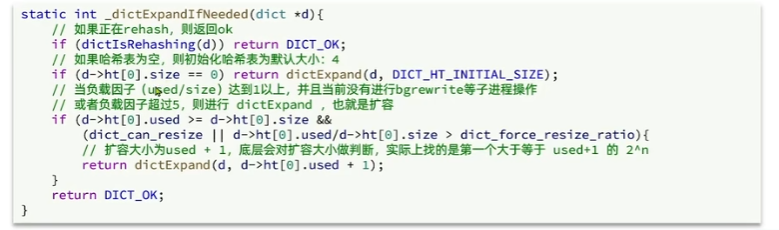
Dict在每次新增键值对时都会检查负载因子(LoadFactor= used/size),满足以下两种情况时会触发哈希表扩容:
- 哈希表的 LoadFactor>=1,并且服务器没有执行BGSAVE 或者BGREWRITEAOF 等后台进程
- 哈希表的 LoadFactor>5;
有扩容就会有收缩

收缩的过程
这里无论扩容还是收缩都要进行rehash(191行)
Dict的rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash。过程是这样的:
-
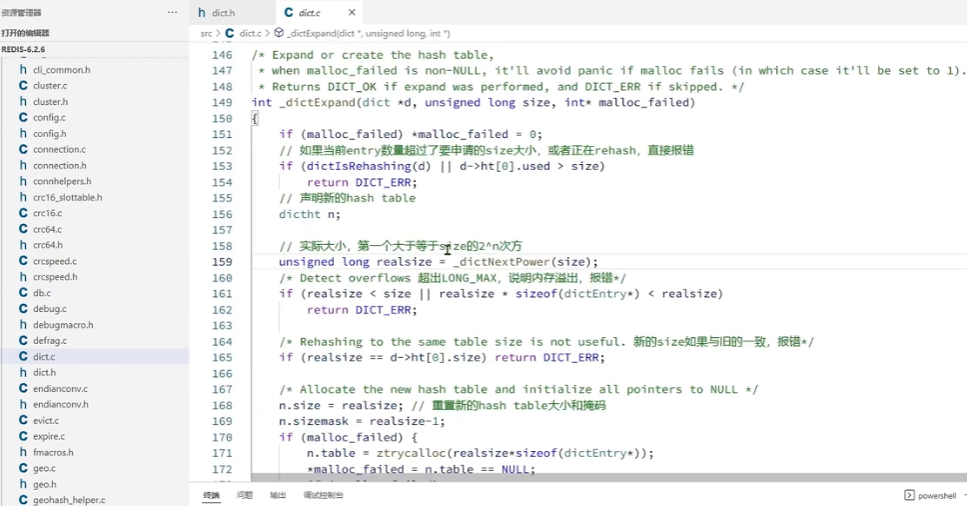
计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0]used +1的2ⁿ
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2ⁿ(不得小于4)
-
按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
-
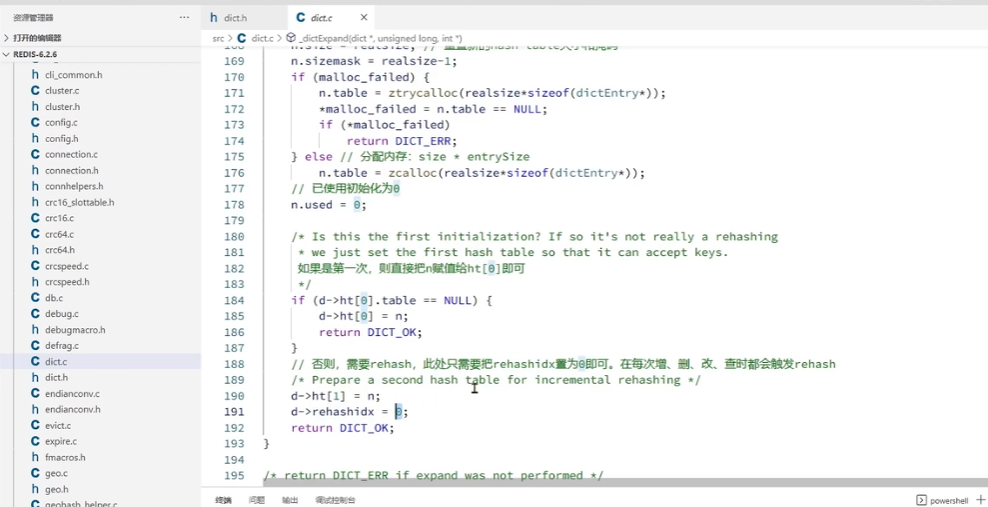
设置dict.rehashidx =0,标示开始rehash
-
每次执行新增、查询、修改、删除操作时,都检查一下dict,rehashidx是否大于-1,如果是则将dict,ht[0].table[rehashidx]的entry链表rehash到dict.ht[1],并且将rehashidx++。直至dict.ht[0]的所有数据都rehash到dict.ht[1]
-
将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
-
将rehashidx赋值为-1,代表rehash结束
-
在rehash过程中,新增操作,则直接写入ht[1],查询、修改和制除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空
rehash图解
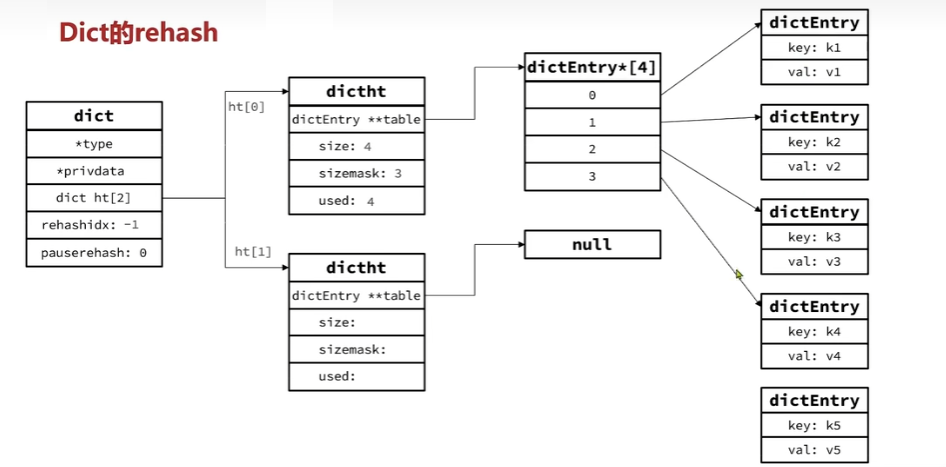
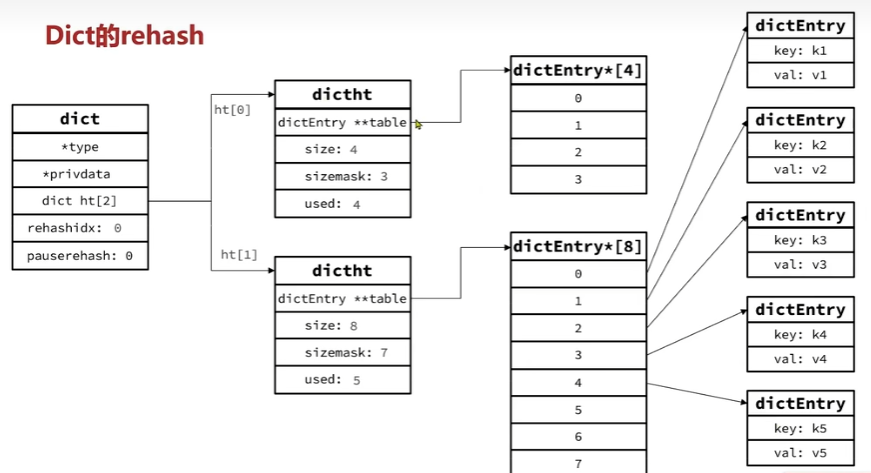
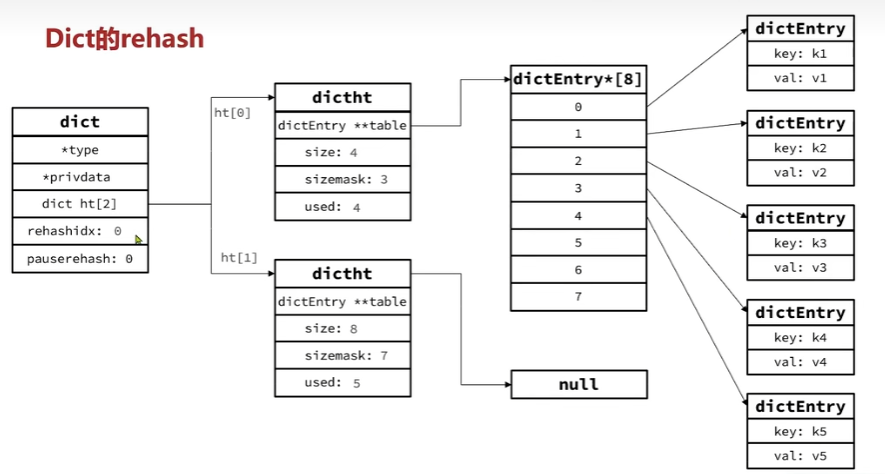
为了减小rehash时造成主线程阻塞的影响
Dict的rehash并不是一次性完成的。试想一下,如果Dict中包含数百万的entry,要在一次rehash完成,极有可能导致主线程阻塞。因此Dict的rehah是分多次、渐进式的完成,因此称为渐进式rehash。也就是上面的第4步处理而每次只迁移一个角标的数据到新的哈希表直到所有数据都迁移完成
在rehash的时候进行修改,查询,删除操作需要到两个哈希表(dict[0]和dict[1])里去查询,而新增和其他三个不一样,上面第7点有提到是直接插入新的哈希表(dict[1])里去
总结
Dict的结构:
- 类似java的HashTable,底层是数组加链表来解决哈希冲突
- Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash
Dict的伸缩:
- 当LoadFactor大于5或者LoadFactor大于1并且没有子进程任务时,Dict扩容
- 当LoadFactor小于0.1时,Dict收缩
- 扩容大小为第一个大于等于used +1的2的n次方
- 收缩大小为第一个大于等于used 的2的n次方
- Dict采用渐进式rehash,每次访问Dict时执行一次rehash
- rehash时ht[0]只减不增,新增操作只在ht[1]执行,其它操作在两个哈希表
redis原理



评论