
2020-05-30
2259

原创
K均值算法--应用
1应用K-means算法进行图片压缩
- 读取一张图片
- 观察图片文件大小,占内存大小,图片数据结构,线性化
- 用kmeans对图片像素颜色进行聚类
- 获取每个像素的颜色类别,每个类别的颜色
- 压缩图片生成:以聚类中收替代原像素颜色,还原为二维
- 观察压缩图片的文件大小,占内存大小 代码如下:
from sklearn.datasets import load_sample_image
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.image as mpimg
import sys
#加载样本图像
# image = load_sample_image('china.jpg')
#加载本地图片
image = mpimg.imread('image2.jpg')
#降维(将二维图片变成一维)
X = image.reshape(-1,3)
print(image.shape,X.shape)
#进行聚类将255*255*255聚成64类
n_colors=64
model=KMeans(n_colors)
#一维(273280, 3)对每一个像素进行分类
labels=model.fit_predict(X)
#将273280分成64类
colors=model.cluster_centers_
new_image=colors[labels].reshape(image.shape)
#显示原图片
plt.imshow(image)
plt.show()
#显示压缩后的图片
new_image=new_image.astype(np.uint8)
plt.imshow(new_image)
plt.show()
#二次压缩(每三个像素取一个)
new_image=new_image.astype(np.uint8)[::3,::3]
plt.imshow(new_image)
plt.show()
print("image Size:",sys.getsizeof(image))
print("new_image Size:",sys.getsizeof(new_image))
import matplotlib.image as img
img.imsave('F:\\01.jpg',image)
img.imsave('F:\\02.jpg',new_image)
原图:

第一次压缩后的图:

第二次压缩后的图:

原图和压缩后的图的大小对比:

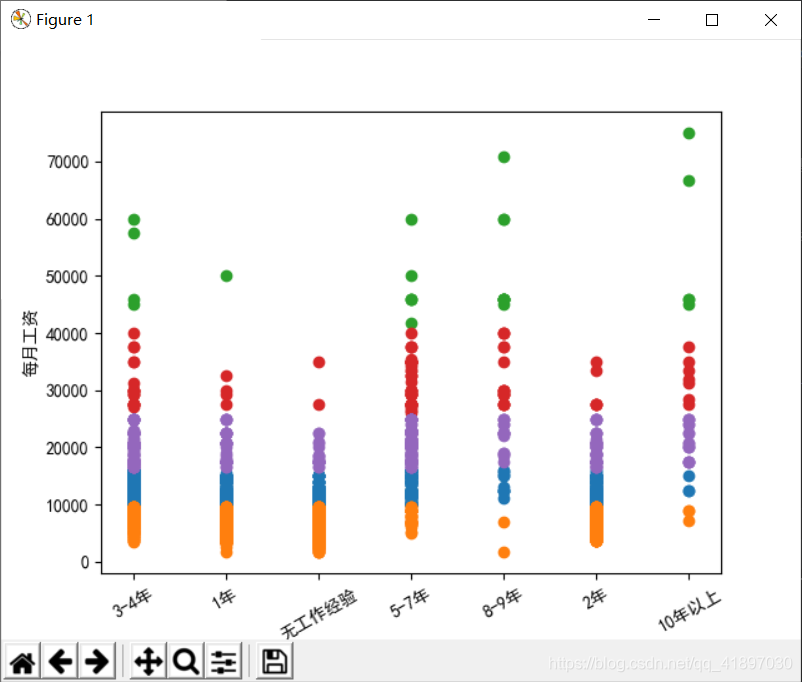
将不同工作经验者的工资进行Kmeans算法归类
- 爬取30000条智联招聘网的招聘信息
import requests
import re
import csv
# https://www.zhipin.com/c101280100/?query=Java
# https://jobs.51job.com/guangzhou/p1/
# <span class="location">10-15万/年</span>
# <div class="e ">\D+</div>
# <p class="info">(.*?)</p>\D+<p class="order">(.*?)</p>
i=1
with open('data.csv', 'a+', newline='', encoding='utf8') as f:
writer = csv.writer(f, dialect="excel")
writer.writerow(['职位','地址','工资','发布日期','学历要求','工作经验','公司性质','公司规模'])
while True:
url = "https://jobs.51job.com/guangzhou/hy01/p"+str(i)+"/"
int(i)
i+=1
print(url)
response = requests.get(url)
if response.status_code!=200:
break
response.encoding='gbk'
data_list = re.findall('<p class="info">(.*?)</p>\D+<p class="order">(.*?)</p>',response.text)
datac = {}
for data in data_list:
# print(data[0])
data1 = re.findall('<a.*?target="_blank".*?>(.*?)</a>.*?<span class="location name">(.*?)</span>.*?<span class="location">(.*?)</span>.*?<span class="time">(.*?)</span>',data[0])
# print(data1)
datac['职位']=data1[0][0]
datac['地址']=data1[0][1]
datac['工资']=data1[0][2]
datac['发布日期']=data1[0][3]
# print(data[1])
data2 = re.findall('学历要求:(.*?)<span>.*?工作经验:(.*?)<span>.*?公司性质:(.*?)<span>.*?公司规模:(.*)',data[1])
# print(data1)
datac['学历要求']=data2[0][0]
datac['工作经验']=data2[0][1]
datac['公司性质']=data2[0][2]
datac['公司规模']=data2[0][3]
if datac:
writer.writerow([datac['职位'],datac['地址'],datac['工资'],datac['发布日期'],datac['学历要求'],datac['工作经验'],datac['公司性质'],datac['公司规模']])
- 处理爬取到的信息
from pandas import read_csv
import re
import csv
import numpy as np
data=read_csv('data.csv')
# dict={}#字典去重
# dict2=[]#地址去重后的存放容器
# #地址去重
# for i in data['工资']:
# i = str(i)#1-1.5万/月
# d=re.findall('\d+.?\d*-\d+.?\d(.*/.*)', i)
# if d:
# dict[d[0]]=0
# for i in dict.keys():
# print(i)
# 查询出来的结果
# 万/月 千/月 万/年
def format(x):
x = str(x)
min1=re.findall('(\d+.?\d*)-(\d+.?\d*)?(千/月)', x)
if min1:
# print(float(min1[0][0])*1000)
min=str(float(min1[0][0])*1000)
max=str(float(min1[0][1])*1000)
return min+"-"+max
min2 = re.findall('(\d+.?\d*)-(\d+.?\d*)?(万/月)', x)
if min2:
# print(float(min2[0][0])*10000)
min=str(float(min2[0][0])*10000)
max=str(float(min2[0][1])*10000)
return min+"-"+max
min3 = re.findall('(\d+.?\d*)-(\d+.?\d*)?(万/年)', x)
if min3:
# print(float(min2[0][0])*10000)
min=str(float(min3[0][0])*10000/12)
max=str(float(min3[0][1])*10000/12)
return min+"-"+max
data['工资']=data['工资'].apply(format)
data[['最低工资','最高工资']]=data['工资'].str.split('-',1,True)
data=data.drop(['工资'],axis=1)#删除工资列
print(data)
data=data.dropna()
data['平均工资']=(data.最低工资.astype(float)+data.最高工资.astype(float))/2
with open('mogong.csv', "w", newline='', encoding='utf8') as f:
writer = csv.writer(f)
writer.writerow(data.columns)
writer.writerows(data.values)
- 用Kmeans算法进行归类
from sklearn.cluster import KMeans
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
data = pd.read_csv('mogong.csv')
# 去重后的存放容器
dict2=[]
sumSalary={}
column=['工作经验']
# 轴坐标存放容器
X = []
#获取样本种类(样本去重)
def getKind(column):
for i in data[column]:
sumSalary[i]=0
for i in sumSalary.keys():
dict2.append(i)
def format(x):
for j in dict2:
if x == j:
return dict2.index(j)+1
def relationCoefficient(column1):
getKind(column1)
data[column1] = data[column1].apply(format)
for i in column:
relationCoefficient(i)
# 备份dict2数据
X=dict2
# 初始化容器
dict2=[]
sumSalary={}
#取6000条进行计算
data = data[['工作经验','平均工资']].astype(int)[0:6000].values
# 构建模型
model = KMeans(n_clusters=5).fit(data)
model.labels_
# 查看聚类效果
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 雅黑字体
for i in range(5):
plt.scatter(data[model.labels_ == i, 0], data[model.labels_ == i, 1])
# 替换坐标
plt.xticks(range(1,len(X)+1),X,rotation=30)
# 设置y轴名称
plt.ylabel("每月工资")
plt.show()
结果图如下
python
算法
大数据



评论